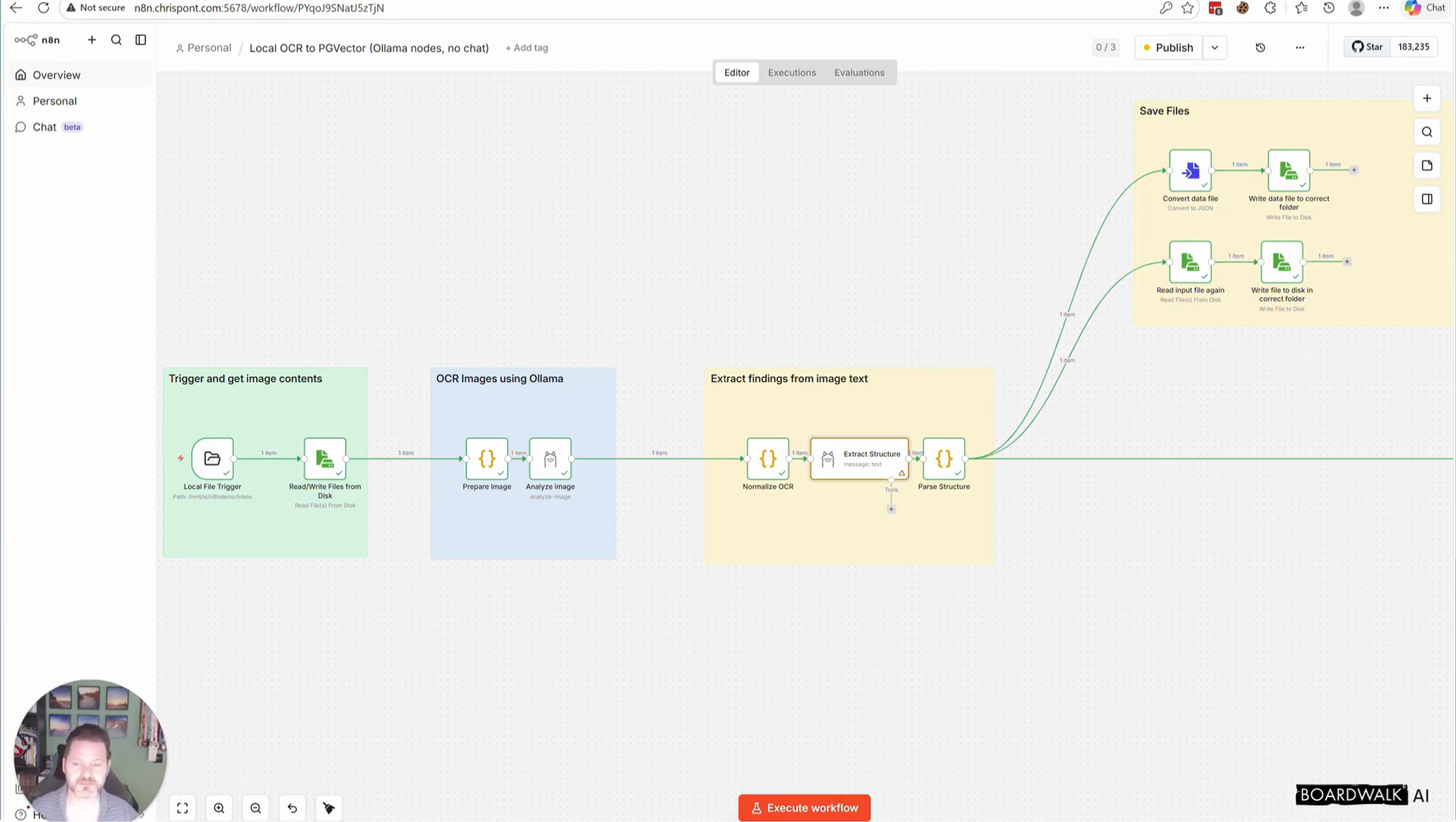
In this video I walk through a local AI workflow that takes a scanned document image, extracts the text, identifies the document type, pulls out structured data, stores embeddings in Postgres, and makes the result searchable through Open WebUI.
This is a practical proof of concept for businesses dealing with shared drives full of files, scanned paperwork, invoices, contracts, and other documents that are hard to organise and search.
Stack used in this demo:
n8n
Ollama
Gemma
PostgreSQL + PGVector
Open WebUI
What the workflow does:
watches for a new scanned image
performs OCR with a local model
extracts structured fields like document type, organisation, date and reference number
files the document
generates embeddings
stores them in PGVector
makes the data searchable through a simple chat interface
This is a proof of concept, not a finished production system. In a real implementation you would also want proper permissions, document retention rules, auditing, error handling, chunking strategy, and access controls.
Scan Paper Documents into Searchable AI Data with n8n, Ollama and Postgres